
今日份论文阅读!
参考:
1.Visual-RFT
2.Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
3.LatentLM-Multimodal Latent Language Modeling with Next-Token Diffusion
LatentLM-Multimodal Latent Language Modeling with Next-Token Diffusion
本文通过在传统的causal transformer结构中引入diffusion实现对离散模态(语言)和连续模态(图像、音频)等的一致处理
1. Causal Transformer(因果Transformer)
- 核心思想:在Transformer结构中引入因果性约束,确保每个位置的输出仅依赖于前面已生成的位置(即自回归顺序)。
- 关键机制:通过位置掩码(Position Masking) 实现。在自回归生成时,每个位置只能看到自身及左侧的位置信息,右侧位置被遮蔽(mask掉),防止信息泄漏。
2.tinuous Vector(连续向量)
- 基本概念:将离散符号(如文本中的单词)或原始连续数据(如图像像素、音频波形)映射到高维连续空间的向量表示。
- 目的:
- 统一模态表示:使离散模态(语言)和连续模态(图像/音频)能在同一模型中处理。
- 降低计算复杂度:通过低维潜在空间(如VAE编码)压缩数据,减少计算量。
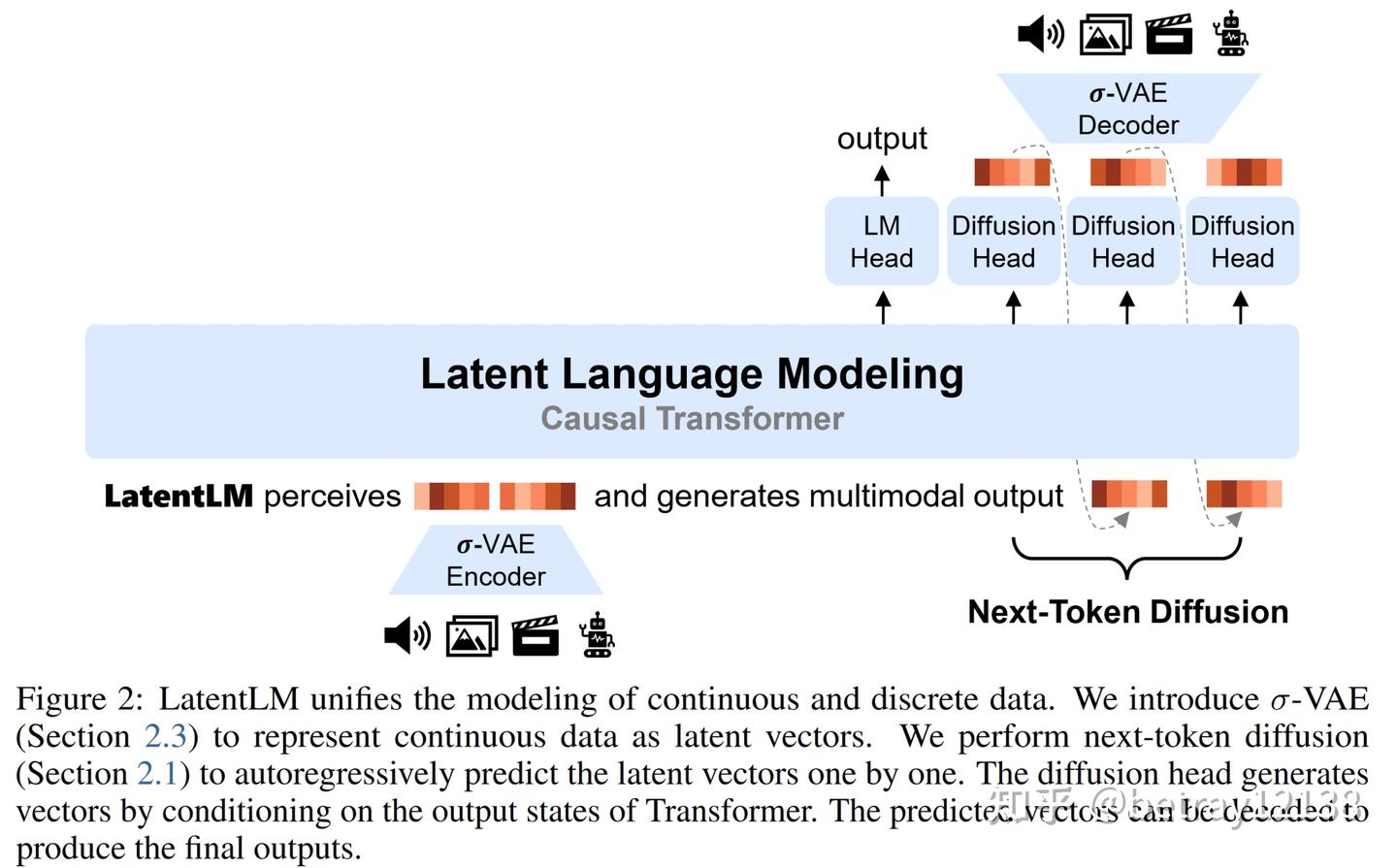
总体结构如下图所示

图 1:Latent Language Modeling (LatentLM) 使用因果 Transformer 无缝处理连续(例如图像、音频、视频)和离散(例如文本和代码)数据。我们引入了 next-token diffusion 来逐个自回归生成潜在向量。所提出的方法提供了一个通用的接口,统一了多模态的生成和理解。
多模态生成模型需要一种统一的建模方法来处理离散数据和连续数据。
以前的大多数系统都依赖于构建管道或调用外部工具。但是,很难对基于管道的方法执行端到端优化。模块之间的信息丢失也会限制性能。 为了在多模态大型语言模型中原生处理离散和连续的数据,有三个主要的研究方向。
1. 基于VQ-VAE的离散化方法
核心思想:通过VQ-VAE将连续数据量化为离散代码,在自回归语言模型中统一建模为离散序列。
代表工作:VQ-VAE、DALL-E、VQGAN等。
流程:
- 编码阶段:使用VQ-VAE编码器将连续数据映射到离散的代码本(Codebook),生成离散代码序列。
- 建模阶段:所有数据(包括原始离散数据)均作为离散token输入自回归模型(如GPT),通过预测下一个token进行训练。
- 解码阶段:利用VQ-VAE解码器将离散代码重建为连续数据。
优势:
- 统一离散和连续数据的表示,简化模型架构。
- 自回归模型在文本生成任务中表现成熟。
局限性:
- 量化损失:VQ-VAE的离散化过程导致信息丢失,形成生成质量的瓶颈。
- 低压缩率:连续数据(如视频)离散化后序列过长,增加计算负担。
- 生成效率:长序列生成需要逐步自回归预测,速度较慢。
2. 基于扩散模型的统一方法
核心思想:将离散数据整合到扩散模型的框架中,利用扩散过程统一生成连续和离散数据。
代表工作:连续数据扩散模型(如DDPM)、离散扩散模型(如D3PM)。
流程:
- 扩散过程:对输入数据逐步添加噪声(连续数据)或扰动(离散数据)。
- 去噪训练:模型学习从噪声中恢复原始数据。
- 统一生成:通过同一扩散框架生成多模态数据。
优势:
- 扩散模型在连续数据生成(如图像、音频)上表现优异。
- 理论上可统一多模态生成流程。
局限性:
- 离散数据建模性能下降:文本等离散数据需依赖自回归或掩码预测机制,扩散框架可能不如传统语言模型高效,其本身不是为了离散数据设计的。
- 训练目标冲突:连续数据的噪声添加与离散数据的扰动机制难以完全兼容,可能导致联合训练不稳定。
3. 共享参数但分治目标的混合方法
核心思想:共享模型主干参数,但针对不同数据类型采用不同训练目标(扩散去噪 vs. 自回归预测)。
代表工作:UniDiffuser、Lumina等。
流程:
- 参数共享:模型主干(如Transformer层)处理所有类型数据。
- 分治目标:
- 连续数据:使用扩散目标(双向注意力,逐步去噪)。
- 离散数据:使用自回归目标(因果注意力,预测下一token)。
- 联合训练:交替优化两种目标,实现多模态生成。
优势:
- 参数共享提升模型容量利用率。
- 灵活适应不同数据类型的生成需求。
局限性:
- 目标冲突:扩散去噪与自回归预测的目标差异可能导致优化方向不一致。
- 架构复杂性:需同时支持双向和因果注意力,增加实现难度。
- 可变长度序列限制:扩散模型的双向注意力难以处理动态生成的序列(如实时语音)。
- 噪声干扰:扩散训练的噪声可能破坏离散数据的联合训练效果。
4. 本文核心方法:Latent Language Modeling (LatentLM)
(1) 统一建模框架
LatentLM的核心目标是通过因果Transformer架构统一处理离散(如文本)和连续(如图像、音频)数据,其核心创新点包括:
- 潜在空间表示:使用VAE将连续数据映射为低维连续向量(Latent Vectors),与离散数据的词嵌入(Word Embedding)共享同一语义空间。
- Next-Token Diffusion:通过扩散模型自回归预测连续数据的潜在向量,与传统语言模型的Next-Token Prediction(Softmax)结合,实现多模态统一生成。
- σ-VAE:改进VAE的潜在空间分布,使其更适合自回归解码。
(2) 技术流程
- 输入处理:
- 离散数据(文本):通过词嵌入转换为连续向量序列。
- 连续数据(图像/音频):通过VAE编码为潜在向量序列。
- 共享Transformer处理:
- 所有模态的潜在向量输入同一因果Transformer,生成联合上下文表示。
- 输出解码:
- 离散数据:使用Softmax Head预测下一个词。
- 连续数据:使用Diffusion Head生成下一个潜在向量,并通过VAE解码器还原原始数据
实际实现中,过程如下:
atentLM的核心设计目标是通过一个统一的Transformer架构,同时支持离散(文本)和连续(图像/音频)模态的生成。其实现流程分为以下步骤:
- 离散数据(文本)处理:
- 传统语言模型(LM)方式:输入文本序列→词嵌入→因果Transformer→LM Head预测下一个词。
- 连续数据(图像)处理:
- VAE编码:图像→潜在向量→因果Transformer→Diffusion Head预测去噪后的潜在向量→VAE解码器重建图像。
整个过程通过共享的因果Transformer实现模态间信息交互,下图展示了这一流程:
其中文章使用的类似VAE结构与原始VAE略有不同,文章中固定了标准差,用于防止训练过程发生collapse。故loss由原本的(1)式转变为了(3)式
$$
maximize\quad \mathbb E_{q_{\phi} (z|x)}[\log p_{\psi}(x|z)-D_{KL}[q_{\phi} (z|x) || p(z)]
$$
$$
minimize ||\hat x-x||^2_2 +\beta ||\mu||^2_2
$$
Visual-RFT: Visual Reinforcement Fine-Tuning
OpenAI o1 等大型推理模型中的强化微调 (RFT) 从其答案的反馈中学习,这在微调数据稀缺的应用程序中特别有用。具有可验证奖励的强化学习是再现 o1 的一个关键方向。在多模态领域的应用仍未得到充分探索。这项工作
引入了视觉强化微调 (Visual-RFT),它进一步扩展了 RFT 在视觉任务上的应用领域。首先使用大型视觉语言模型 (LVLM) 生成多个响应,其中包含每个输入的推理标记和最终答案,
提出视觉感知可验证奖励函数通过策略优化算法(如组相对策略优化 (GRPO))来更新模型。
不同的感知任务设计了不同的可验证奖励函数,例如用于对象检测的交集 (IoU) 奖励。
与监督微调 (SFT) 相比,Visual-RFT 具有竞争力的性能和先进的泛化能力。
大型推理模型(LRMs)与强化微调(RFT)的深度解析
1. 大型推理模型(LRMs)的定义与核心能力
大型推理模型(LRMs) 是一类专注于复杂多步推理任务的前沿AI模型,其核心目标是通过延长“思考”时间(即增加推理步骤或优化内部决策机制)提升模型在数学证明、逻辑推理、代码生成等任务中的表现。典型代表如 OpenAI o1,其设计理念强调在生成最终答案前进行更深入的内部推理。
关键特征:
• 多步推理能力:通过链式思考(Chain-of-Thought)、思维树(Tree-of-Thoughts)或自省机制(Self-Refinement)模拟人类的多步推理过程。
• 模块化架构:可能包含推理模块(如符号逻辑引擎)与生成模块(如Transformer)的协同工作。
• 延迟生成策略:在输出答案前执行多次内部计算或验证步骤。
2. 强化微调(RFT)的核心机制
强化微调(RFT) 是一种针对预训练语言模型(LLMs)的高效微调方法,其核心思想是通过强化学习(RL)优化模型在特定任务中的表现,仅需少量样本即可实现领域适应。与传统RLHF(基于人类反馈的强化学习)相比,RFT的突破在于样本效率和规则驱动。
RFT与传统RLHF的对比:
| 维度 | 传统RLHF | RFT |
|---|---|---|
| 奖励来源 | 基于人类偏好数据训练的奖励模型 | 由预定义规则直接计算(Verifiable Rewards) |
| 数据需求 | 需大量标注的偏好数据(如数万条) | 仅需少量任务样本(几十至几千条) |
| 适用场景 | 通用任务(如对话安全性、创意生成) | 领域特定任务(如数学解题、代码生成) |
| 可解释性 | 低(依赖黑盒奖励模型) | 高(奖励规则透明) |
RFT实现步骤:
- 任务定义:明确领域任务的输入输出格式(如数学问题→解题步骤→答案)。
- 规则化奖励设计:将任务成功标准编码为可计算的奖励函数(如答案正确性、步骤规范性)。
- 策略优化:通过PPO等RL算法,最大化模型输出在奖励函数下的得分。
3. 可验证奖励(Verifiable Rewards)的技术创新
可验证奖励 是复现类似o1模型的关键技术,其核心在于通过预定义规则直接计算强化学习中的奖励分数,而非依赖独立训练的奖励模型。这一方法在开源研究(如DeepSeek R1)中已被验证有效。
典型应用场景:
• 数学推理:答案正确性可通过符号计算验证(如SymPy库自动评分)。
• 代码生成:奖励基于代码能否通过测试用例(如LeetCode评测)。
• 逻辑证明:奖励取决于推理步骤是否符合形式逻辑规则。
技术优势:
• 减少数据依赖:无需收集人类偏好数据,降低标注成本。
• 消除奖励模型偏差:直接使用确定性规则,避免奖励模型的预测误差。
• 提升训练稳定性:规则化奖励提供明确的优化信号,加速收敛。
4. 可验证奖励 vs. 传统奖励模型
| 对比项 | 传统奖励模型 | 可验证奖励 |
|---|---|---|
| 训练数据 | 需要人类标注的偏好数据(如A/B测试结果) | 无需额外数据,依赖预定义规则 |
| 适用范围 | 主观性任务(如文本流畅性、创意评分) | 客观性任务(如数学、代码、科学问题) |
| 计算开销 | 需额外训练和部署奖励模型 | 直接调用规则函数,无额外模型推理成本 |
| 可迁移性 | 跨任务泛化能力有限 | 规则可复用至同类任务(如不同编程语言代码生成) |
5. 复现o1的技术路径:以DeepSeek R1为例
开源研究(如DeepSeek R1)揭示了复现o1的可能方向:将可验证奖励与多步推理架构结合。
关键技术步骤:
- 架构设计:
• 推理模块:集成符号计算库(如Wolfram Alpha API)或形式化验证工具。
• 生成模块:基于Transformer的LLM,负责生成候选答案。
• 验证模块:自动执行规则检查(如代码测试、数学验证)。 - 训练流程:
• 预训练:在通用语料上训练基础LLM。
• RFT微调:使用可验证奖励优化特定任务(如仅用100条数学题样本)。 - 推理优化:
• 延迟生成:模型生成中间步骤后,调用验证模块检查正确性,若失败则重新推理。
• 自省机制:根据验证结果动态调整生成策略(如优先选择已验证正确的子步骤)。
SFT 范式$\rightarrow$依赖于大量的训练数据
RFT $\rightarrow$评估模型的响应,根据它们是否正确调整,通过反复试验来学习
因此,RFT 在数据稀缺的领域特别有用 [7, 24]。
实现细节:
1.对于每个输入,Visual-RFT 使用大型视觉语言模型 (LVLM) 生成包含推理标记和最终答案的多个响应(轨迹)。
2.我们定义了特定于任务的、基于规则的可验证奖励函数,以指导策略优化,例如 GRPO [31],以更新模型。例如,我们建议为对象检测任务提供交集与联合 (IoU) 奖励。我们的 Visual-RFT 与 SFT 形成鲜明对比,后者依赖于记住正确答案。
3.我们的方法将训练范式从 SFT 中的数据扩展转变为针对特定多模态任务量身定制的可变奖励函数的战略设计。如图 2 (c) 所示,可验证奖励和视觉感知能力(例如,检测、接地、分类)的协同组合使我们的模型能够在详细的推理过程的帮助下实现对新概念的快速和数据高效掌握。

Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
一、研究背景与挑战
VLAs的优势:
• 通过在大规模机器人数据集上微调预训练的视觉-语言模型,VLAs展现出强大的跨机器人/任务泛化能力
• 具备优秀的语义理解和指令遵循能力现存核心问题:
• 微调是部署VLAs到新场景的关键,但缺乏有效方法论指导
• 直接沿用预训练策略未必最优,且缺乏替代方案的实证研究
二、现有技术局限性
参数微调困境:LoRA等参数高效方法虽节省计算资源,但自回归生成导致3-5Hz的低频响应,全量微调同样面临双臂操作任务中的性能瓶颈
加速技术的局限:新型动作编码方案(如符号化处理)将速度提升2-13倍,但是仍存在显著延迟(如FAST方案750ms),难以满足高频控制需求(>2550Hz)
三、本研究创新点
(一)三大核心设计维度
| 设计维度 | 选项对比 | 实验发现 |
|---|---|---|
| 动作解码方式 | 自回归 vs 并行生成 | 并行解码+分块技术:速度提升&成功率提高,输入输出更灵活 |
| 动作表征形式 | 离散 vs 连续 | 连续动作显著提升模型质量 |
| 学习目标函数 | 下一token预测/L1回归/扩散 | L1回归兼具训练快、收敛优、推理速的特点,性能接近扩散方法 |
(二)关键技术突破
- 并行解码架构:
• 采用分块处理消除自回归等待时间
• 在保持精度前提下实现实时响应(推测可达毫秒级延迟) - 连续动作空间优化:
• 相比离散编码(如关节角度离散化),连续建模能更好捕捉平滑运动轨迹
• 特别适合机械臂这类需要精细控制的场景 - L1回归优势:
• 训练速度比扩散方法提升数倍
• 推理时无需迭代采样,直接输出确定性动作
• 在保证任务成功率的同时降低计算负载
二、L1回归——让机器人学会“直接回答问题”
1. 传统生成式方法(如GPT)的痛点
• 问题:当用语言模型预测动作时,模型会像聊天一样逐字生成(比如先预测“向前走”,再预测“右转”)。
• 缺陷:
◦ 低频响应:每一步都要等待前一步生成,导致动作频率低下(如每秒只能生成几步)。
◦ 随机性干扰:生成的动作可能包含不合理的小概率选项(比如“跳跃着拿杯子”)。2. L1回归的核心思想
• 目标:把动作预测变成一个“填空题”而非“作文题”。
◦ 传统生成式模型:模型需要写出完整的动作序列(如“向前走→右转→拿起杯子”)。
◦ L1回归:直接给模型一个空白(如“→_→_”),让它填入正确的动作数值(如[0.5m/s, 30°, 0.2N])。
• 数学表达:
$$
\text{Loss} = \sum{t=1}^T | \hat{a}_t - a_t^{\text{true}} |_1
$$
→ 目标是最小化预测动作$\hat{a}_t$与真实动作$a_t^{\text{true}}$的绝对误差之和。
三、方法创新:OpenVLA-OFT与OFT+框架
(一)核心技术集成
- 并行解码 + 动作分块
- 技术原理:打破传统自回归生成顺序依赖,通过分块处理允许并行计算多个动作片段
- 优势:
- 推理延迟降低至毫秒级(如25步分块实现43×加速)
- 输入输出灵活性增强(支持非固定长度动作序列)
- 连续动作表征
- 采用高维连续空间(如关节角/末端位姿)替代离散编码
- 关键价值:更好建模机械臂的平滑动力学特性,与物理引擎的闭环控制更兼容
- L1回归目标函数
- 直接预测动作值而非语言模型的下一token
- 优化效益:训练速度提升3-5倍(对比扩散方法)。推理时无需迭代采样,确定性强
(二)扩展方案OFT+
- 核心增强:引入FiLM(Feature-wise Linear Modulation)模块
- 功能:通过语言提示动态调制特征图,强化多模态语义对齐
- 适用场景:需要精准理解复杂指令的真实世界任务